





この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第146回)は、オンデバイス上で直接動作するローカルAI「MiniCPM5-1B」や、画像内の物体を高速・高精度で見つけ出す視覚言語モデル「LocateAnything」を取り上げます。
また、AIエージェントに与える“スキル”を最適化する手法「SkillOpt」や、マルチプレイのゲーム環境をリアルタイムにAI生成するNVIDIA開発の世界モデル「γ-World」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、1枚の画像と音声データから自然に話すアバター動画を生成するオープンソースAI「LongCat-Video-Avatar 1.5」を別の単体記事で取り上げています。

オンデバイス上で直接動作するローカルAI「MiniCPM5-1Bが同規模の有力オープンモデルで最高性能。デスクトップ型ペットも提供
スマートフォンや一般的なPCなどのリソースが限られた状況でも動かしやすい、約10億(1B)パラメータのオープンソース言語モデル「MiniCPM5-1B」がOpenBMBよりリリースされました。
同じモデルでありながら高速に応答する一般的なアシスタントと、思考プロセスを挟んで慎重に推論するモデルを切り替えて使用することができます。
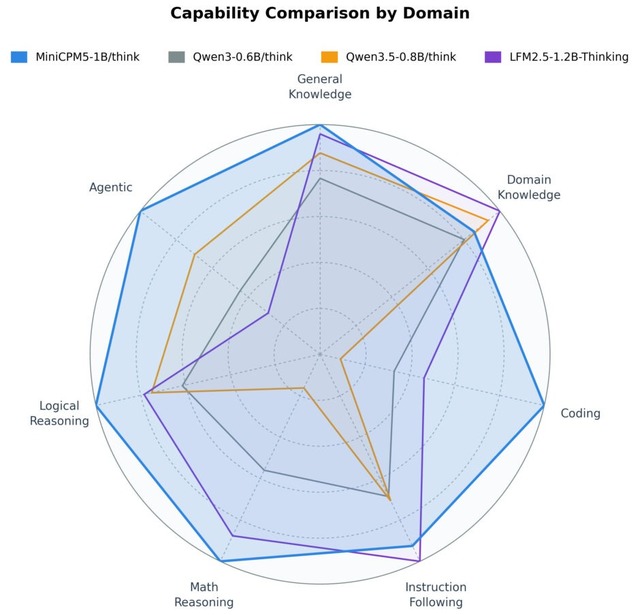
評価テストでは、LFM2.5-1.2B-ThinkingやQwen3-0.6B/think、Qwen3.5-0.8B/thinkといった、同サイズの有力オープンソースモデルとの比較が行われました。その結果、比較対象の中で1Bクラスにおける最高水準(SOTA)の性能を達成しています。
さらに、MiniCPM5-1Bでローカル駆動するデスクトップ型ペット「MiniCPM-Desk-Pet」も提供されています。


MiniCPM5-1B
OpenBMB
GitHub | Hugging Face
AIエージェントに与える“スキル”を最適化する手法「SkillOpt」をMicrosoftなどが開発
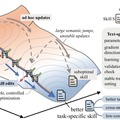
Microsoftや上海交通大学などの研究チームは、AIエージェントに与えるスキル(作業手順やルールのテキスト)を自動で最適化し、進化させる技術「SkillOpt」を発表しました。
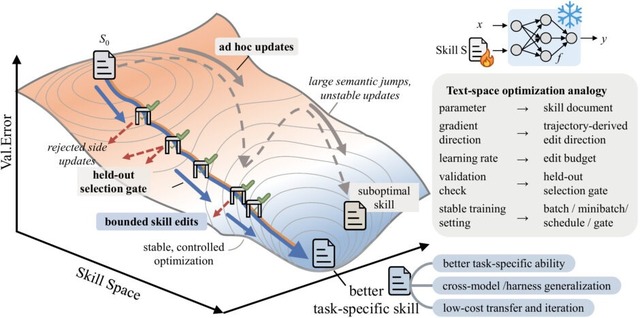
これまで、AIに特定のタスクをこなさせるための指示書は、人間が手作業で作るか、AIに一度だけ生成させるなどが一般的でした。しかし、この方法では実行時の失敗から学んで継続的に手順を改善することが困難でした。
SkillOptは、AIモデル自体の複雑な内部パラメータ(重み)は一切変更せず、外部から与えるテキストの指示書を少しずつ洗練させていく手法です。
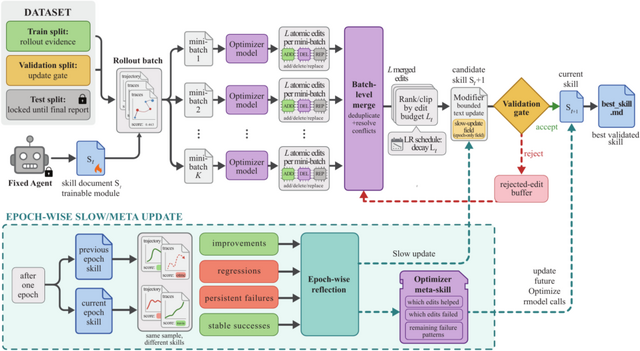
仕組みとしては、タスクを実行するAIとは別に、最適化役のAIを用意します。実行役のAIが現在のスキルを使って作業した後、最適化役のAIがその成功と失敗の履歴を分析し、スキルの改善案を提案します。
提案された新しいスキルは検証用のデータでテストされ、実際に成績が上がった場合のみ正式に採用されます。不採用になった編集内容も失敗例としてメモリに記録され、次の改善に向けたフィードバックとして活用されます。
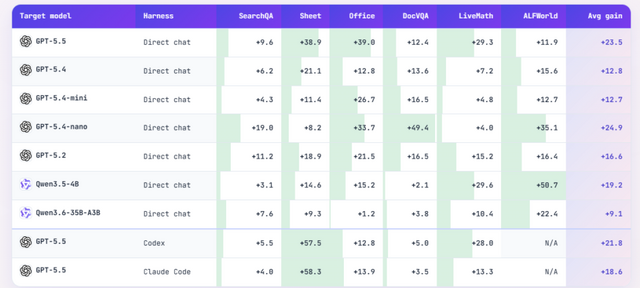
SkillOptで作ったスキルが本当に役立つのかを、6種類のタスク・7つのモデル(GPT-5.5から小規模なQwenまで)・3つの使い方(普通のチャット、Codex、Claude Code)という条件で検証しました。その結果、52通りの組み合わせ全てで最良または同率トップとなり、比較した全ての手法と同等以上の成績を収めました。
SkillOpt: Executive Strategy for Self-Evolving Agent Skills
Yifan Yang, Ziyang Gong, Weiquan Huang, Qihao Yang, Ziwei Zhou, Zisu Huang, Yan Li, Xuemei Gao, Qi Dai, Bei Liu, Kai Qiu, Yuqing Yang, Dongdong Chen, Xue Yang, Chong Luo
Project | Paper | GitHub
画像内の物体を高速・高精度で見つけ出す視覚言語モデル「LocateAnything」をNVIDIAなどが発表
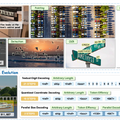
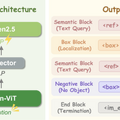
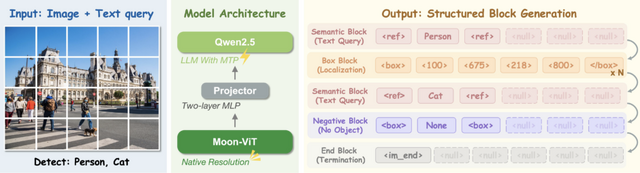
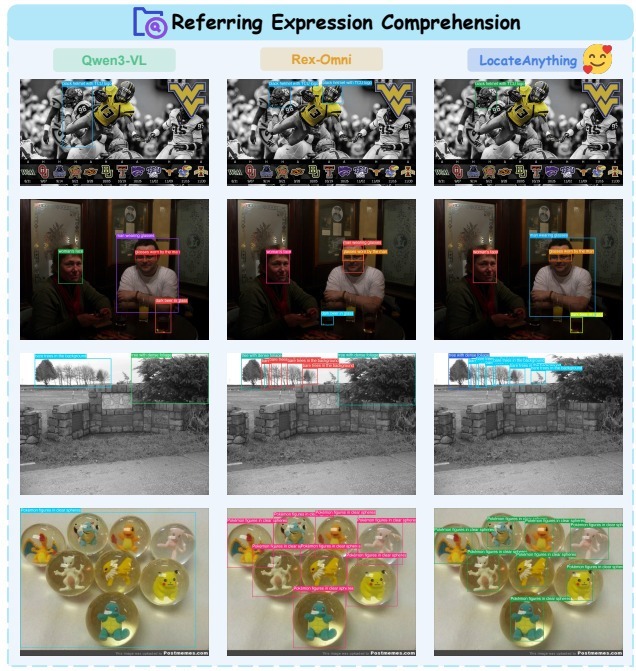
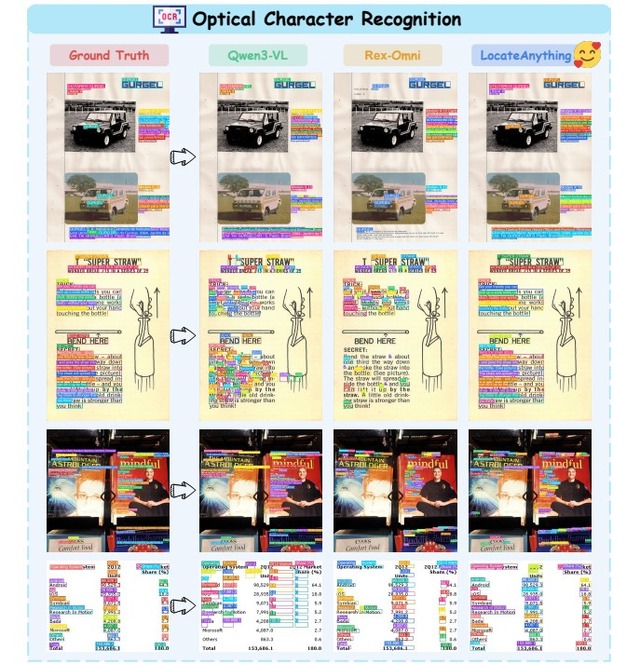
NVIDIAなどの研究チームは、画像内の指定された物体を高速かつ高精度に見つけ出す視覚言語モデル(VLM)「LocateAnything」を発表しました。
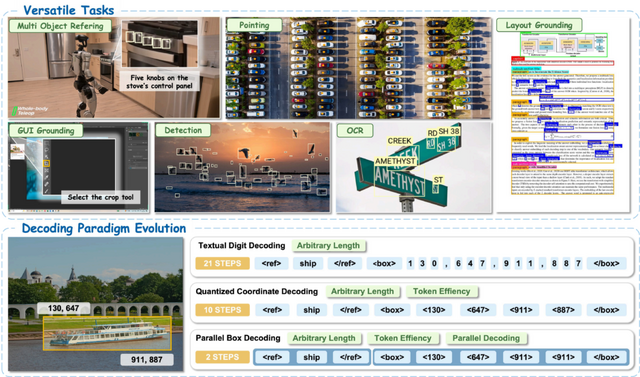
従来のモデルでは、物体の位置を示す枠(バウンディングボックス)の座標を、文章を生成するように1つのトークンずつ順番に予測していました。しかし、この直列的な処理ではどうしても生成に時間がかかってしまい、座標同士の図形的なつながりをAIがうまく学習しきれないという問題がありました。
この課題を解決するため、LocateAnythingはParallel Box Decodingという新しいアプローチを採用しています。これは、物体の位置を示す4つの座標データを分割できないひとつのまとまりとして扱い、1回のステップで一気に並列して予測する手法です。
これにより、処理時間のボトルネックが解消されるだけでなく、空間的なまとまりをAIがより正確に捉えられるようになりました。
モデルの学習には、1億3800万件以上のクエリを収録した専用データセットが用いられました。これにより、一般的な物体の検出にとどまらず、デバイス画面のUI要素の特定、書類のレイアウト解析、細かい文字の認識など、幅広いタスクに対応可能です。同規模の従来モデルと比べて最大2.5倍の処理速度を達成しました。

LocateAnything: Fast and High-Quality Vision-Language Grounding with Parallel Box Decoding
Shihao Wang, Shilong Liu, Yuanguo Kuang, Xinyu Wei, Yangzhou Liu, Zhiqi Li, Yunze Man, Guo Chen, Andrew Tao, Guilin Liu, Jan Kautz, Lei Zhang, Zhiding Yu
Project | Paper | GitHub | Hugging Face
マルチプレイのゲーム環境をリアルタイムにAI生成、NVIDIAなどが世界モデル「γ-World」発表
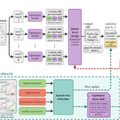
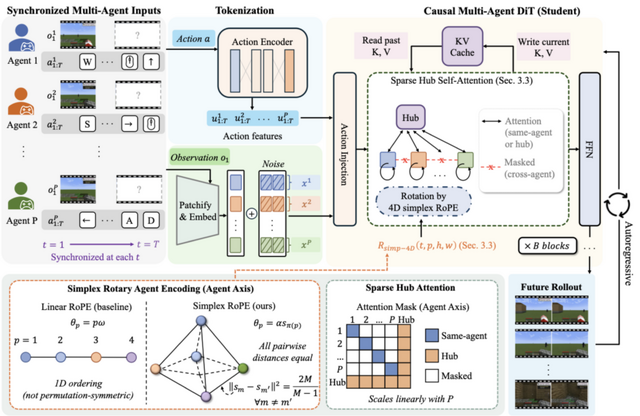
NVIDIAや清華大学などの研究チームは、複数のプレイヤーが同じ空間でやり取りする環境をリアルタイムでシミュレーションできる世界モデル「γ-World」を発表しました。
これまでの世界モデルは主に1人の操作者を想定しており、複数人を同時に処理しようとすると計算量が膨大になるため、2人以上のマルチプレイへと拡張するのが難しいという課題がありました。
この壁を越えるため、γ-Worldは2つの仕組みを取り入れています。1つ目は、従来のように各キャラクターに固定の順番や固有のIDを割り当てるのではなく、数学的な空間上で全員が均等な距離になるよう配置してAIに認識させます。これにより、特定の順番や誰がどの枠にいるかという制限に縛られることなく、複数のキャラクターを対等かつ柔軟に扱えるようになりました。
2つ目は、キャラクター全員が互いの動きを直接一つ一つ計算し合うと処理が重すぎるため、情報を集約する共有のハブを間に設けています。各キャラクターはこのハブとだけ情報をやり取りして全体を把握するため、人数が増えても計算量の増加を抑えることに成功しました。
これらの仕組みに処理を高速化する技術を合わせることで、ユーザーの操作などに反応して、毎秒24フレームの滑らかな映像をリアルタイムで生成できるようになっています。しかも2人用で学習したものを、追加学習なしで4人用に拡張できたことも報告しています。



Gamma-World: Generative Multi-Agent World Modeling Beyond Two Players
Fangfu Liu, Kai He, Tianchang Shen, Tianshi Cao, Sanja Fidler, Yueqi Duan, Jun Gao, Igor Gilitschenski, Zian Wang, Xuanchi Ren
Project | Paper | GitHub


















