


1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第33回目は、生成AI最新論文の概要5つを紹介します。
生成AI論文ピックアップ
訓練なしで複数キャラを同時に異なるプロンプトで量産できる画像生成AI「ConsiStory」、NVIDIAなどが技術開発
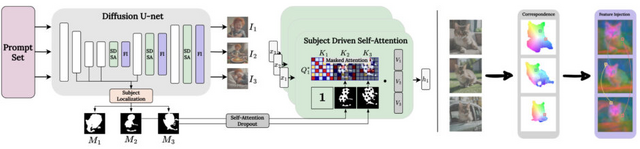
ConsiStoryは、テキスト指示に基づいて画像を生成する際、同じキャラクター(人物や動物、物など)を異なるシナリオで一貫して描画する技術です。この技術により、同一キャラクターの異なる画像を、異なるプロンプトに応じて、細部に至るまで一貫性を保ちながら量産することが可能です。
従来は事前学習や個別にモデルを微調整することで、人物ごとの長期にわたる最適化や大規模な事前トレーニングを必要としていましたが、ConsiStoryはその手間を解決します。また従来の手法では難しかった、複数のキャラクターを一貫して描画することもできます。
この手法は、まず生成された画像内のキャラクターを特定し、これらのキャラクター情報を画像間で共有することで、一貫したキャラクターの表現を強化します。キャラクター間の視覚的一貫性を高めるために、一つの画像から別の画像へ特定の特徴を注入します。さらに、レイアウトの多様性を保つための戦略を採用し、生成される画像が一貫性を保ちつつも、異なるシナリオや背景を持つことができるようにしています。
ConsiStoryは、既存の画像編集ツールとも互換性があり、生成した画像に対してさらに細かい編集を行うことが可能です。これにより、ユーザーは、事前学習や微調整なしに、テキストから被写体を固定した異なるシナリオの高品質な画像コンテンツを生成することができます。





Training-Free Consistent Text-to-Image Generation
Yoad Tewel, Omri Kaduri, Rinon Gal, Yoni Kasten, Lior Wolf, Gal Chechik, Yuval Atzmon
Project | Paper
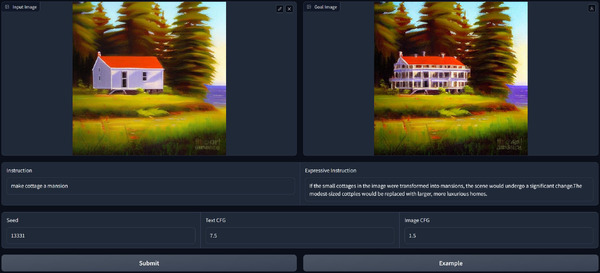
“あいまいな言葉”で画像を合理的に編集できるモデル「MGIE」、Appleなどが開発
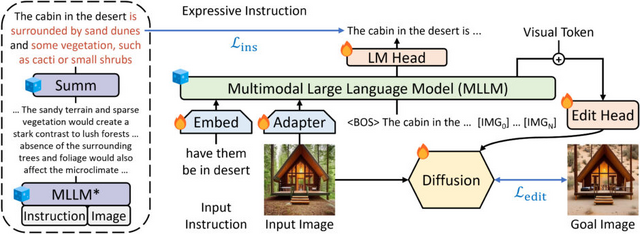
UC Santa BarbaraやAppleなどの研究者たちは、マルチモーダル大規模言語モデル(MLLM)を基にした画像編集手法「MGIE」(MLLM-Guided Image Editing)を開発しました。
MGIEは、MLLMを活用して入力された抽象的な自然言語によるテキストからより詳細で具体的な編集指示を導き出します。これにより、編集目標に対する明確な視覚関連のガイダンスが提供され、拡散モデルを用いたエンドツーエンドのトレーニングを通じて、意図した画像編集が実現されます。
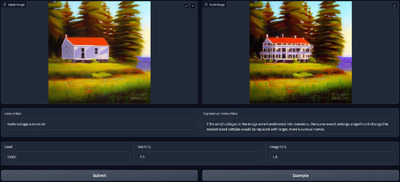
MGIEは、画像の切り取りや明るさ、コントラスト調整などの一般的な画像編集から、画像内の特定のオブジェクトの削除や追加などの部分的な編集まで行えます。これらの編集は、不正確であいまいなテキストでも視覚的に理解し、適切に解釈して編集を行います。
例えば、「プロフェッショナルに見せて」「図書館のようにして」「ヘルシーにして」「バチカンのようにして」などの抽象的な命令に対しても合理的な画像編集を行います。これにより、ユーザーは直感的に画像を編集できるようになります。
実験結果は、自動評価指標と人間による評価の両方で、MGIEが指示に基づく画像編集を顕著に改善し、視覚に関するガイダンスがこの改善に不可欠であることを示しています。

Guiding Instruction-based Image Editing via Multimodal Large Language Models
Tsu-Jui Fu, Wenze Hu, Xianzhi Du, William Yang Wang, Yinfei Yang, Zhe Gan
Project | Paper | GitHub | Demo
Gemini UltraやGPT-4に匹敵する数学特化のオープンソース言語モデル「DeepSeekMath」
数学的な問題を解くことは、その複雑さと厳密な構造のため、言語モデルにとって難しい課題です。この研究では、この課題に取り組むために数学的推論に特化したオープンソースな言語モデル「DeepSeekMath」を開発しました。
具体的には、DeepSeek-Coder-Base-v1.5 7Bの事前学習を継続する新しいモデル「DeepSeekMath 7B」を作成。このモデルは、Common Crawlから収集された120Bの数学関連トークンを含む大規模な事前学習コーパス「DeepSeekMath Corpus」を使用しています。
さらに、数学的推論能力を強化するために、Proximal Policy Optimization(PPO)を基にしつつ、いくつかの改良を加えた新しい形式「Group Relative Policy Optimization」(GRPO)を導入しました。
GRPOの主な特徴は、複数のサンプルをグループとして扱い、それらの相対的な評価を通じてポリシーを更新することです。この方法により、各サンプルの価値をより正確に判断し、メモリ使用量を最適化しながら数学的推論能力を高めることができます。
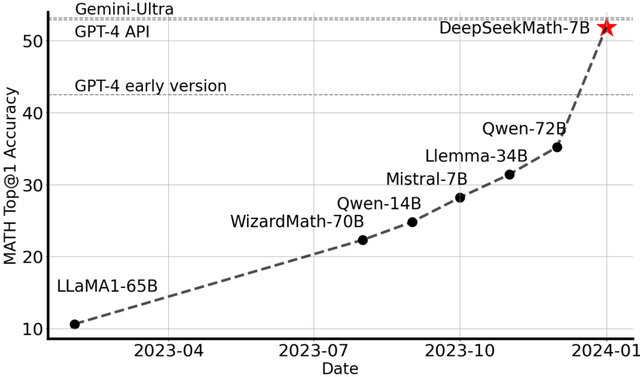
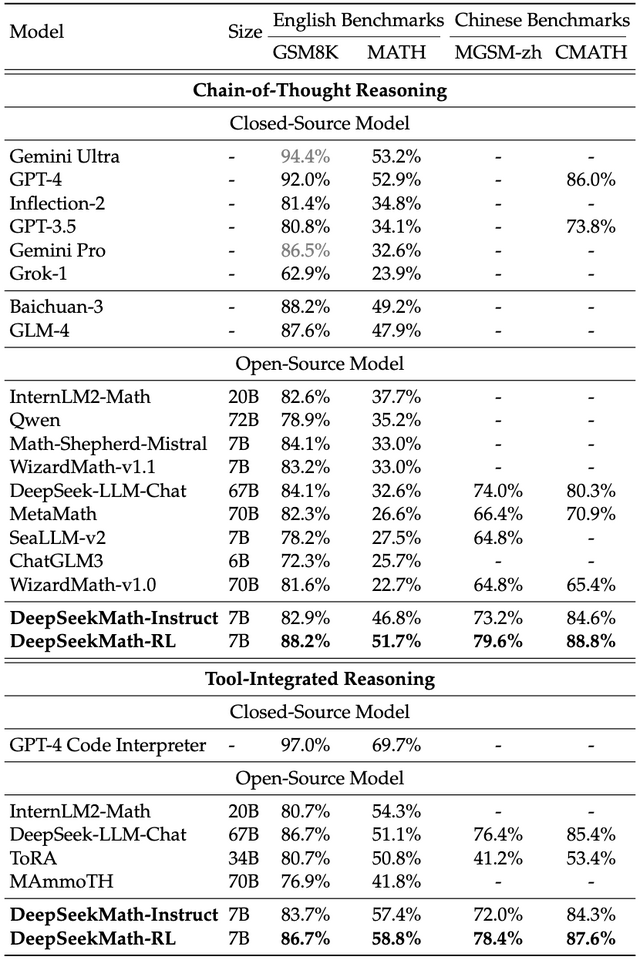
DeepSeekMath 7Bは、外部ツールキットに頼ることなく、競争レベルのMATHベンチマークで51.7%という高いスコアを達成しました。これは、Gemini UltraやGPT-4のパフォーマンスレベルに迫るものです。
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y.K. Li, Y. Wu, Daya Guo
Paper | GitHub
Google、探索アルゴリズムを使わずチェスのグランドマスターレベルを達成するAIモデルを発表
強力なチェスAIの開発において、Stockfish 16やAlphaZeroのようなシステムは、それぞれが独自の方法で高度なチェス戦略を実行します。Stockfishは探索アルゴリズムとヒューリスティックスを利用し、AlphaZeroは自己対戦による学習を通じて、豊富なチェス知識を必要とせずに戦略を獲得します。
この研究では、これらのアプローチとは異なり、豊富なチェス知識や探索アルゴリズムに頼ることなく、大規模なデータセットとトランスフォーマーモデルを使用してチェスのゲームを学習する新たなシステムを開発しました。
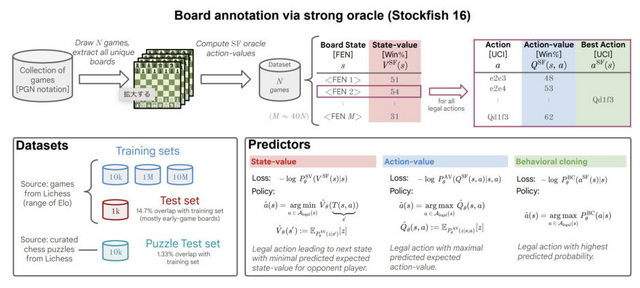
具体的には、約1000万局のチェスゲームから構成されるデータセットを利用し、各局面での最適な手法(アクション値)をStockfish 16によって評価し注釈付けすることで、合計約150億のデータポイントを集めました。この豊富なデータを基に、270Mパラメータのトランスフォーマーモデルの学習を行いました。
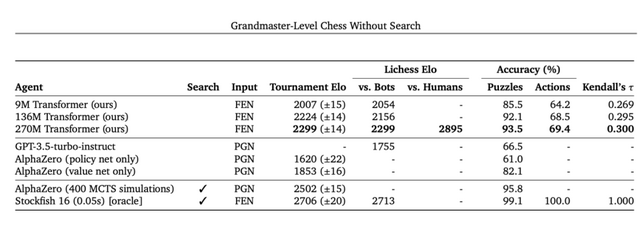
このAIシステムは、オンラインチェスプラットフォーム「Lichess」で人間のプレイヤーと対戦し、Eloレーティング2895を達成しました。このスコアはグランドマスターレベルに匹敵し、AIが高度なレベルでチェスをプレイできることを証明しています。この成果は、AlphaZeroやGPT-3.5-turbo-instructといった既存のモデルを上回るものです。
この研究は、大規模なアーキテクチャとデータセットを用いることで精度が向上するという現象が、チェスのように複雑な戦略が求められる領域にも適用できる可能性を示唆しています。

Grandmaster-Level Chess Without Search
Anian Ruoss, Grégoire Delétang, Sourabh Medapati, Jordi Grau-Moya, Li Kevin Wenliang, Elliot Catt, John Reid, Tim Genewein
Paper
テキストや写真から高解像度の3Dモデルを数秒で生成するモデル「LGM」
現在の3D生成技術は手作業を以前より大幅に削減し、3Dアーティストだけでなく専門知識を持たない人々も3Dアセットの作成に参加できるようにしました。しかし、これらの技術は生成速度が遅く、多様性に欠け、細部の表現が不足しているという問題を抱えています。
これらの課題に対処するため、本研究ではテキストプロンプトまたは単一視点画像から高解像度の3Dモデルを生成可能な新しいフレームワーク「Large Multi-View Gaussian Model」(LGM)を提案します。
LGMは、NeRFやトランスフォーマーに依存した従来の方法と異なり、多視点画像から情報を収集して高解像度で詳細な3Dオブジェクトを生成する「3D Gaussian Splatting」と、高速で効率的な「非対称U-Net」バックボーンを採用しています。
具体的には、テキストや画像から生成された複数視点の画像を入力として、非対称U-Netを使用して4セットの3Dガウスを予測します。これらのガウスは統合され、最終的な3Dモデルを形成します。生成された3Dガウスはオプションで多角形メッシュに変換され、下流タスクに適しています。
実験により、LGMは最大6万5536のガウスを使用して約5秒で高解像度の3Dオブジェクトを生成でき、従来の方法と比較して高い忠実度と効率性を実現しています。



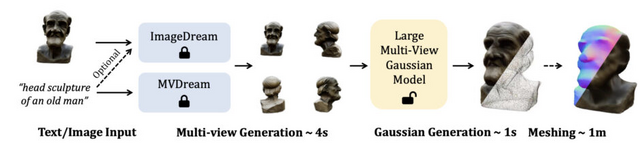
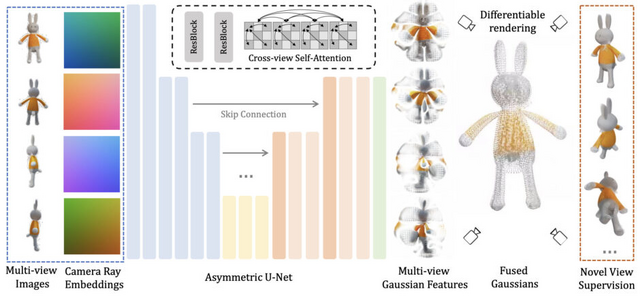
LGM: Large Multi-View Gaussian Model for High-Resolution 3D Content Creation
Jiaxiang Tang, Zhaoxi Chen, Xiaokang Chen, Tengfei Wang, Gang Zeng, Ziwei Liu
Project | Paper | GitHub | Demo