
1週間の気になる生成AI技術・研究をいくつかピックアップして解説する連載「生成AIウィークリー」から、特に興味深いAI技術や研究にスポットライトを当てる生成AIクローズアップ。
今回は、Baiduの研究チームが開発した、数十ページのPDFなど長文を一括処理できるエンドツーエンドのOCRモデル「Unlimited OCR」を取り上げます。このモデルはMITライセンスで公開されており、商用利用も可能です。
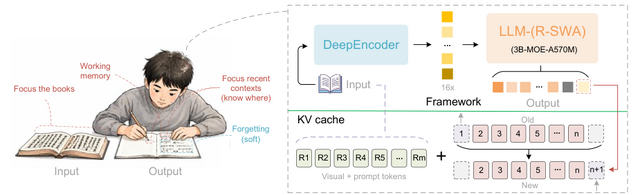
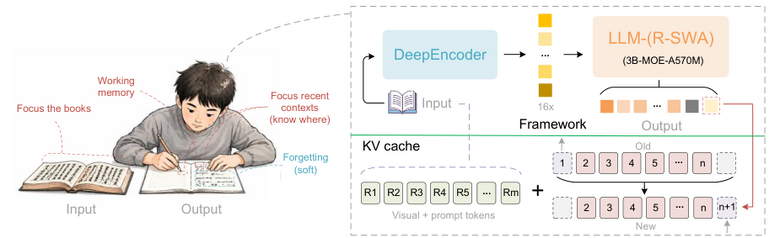
▲人間が本を書き写す際のワーキングメモリを模したUnlimited OCRの構成図
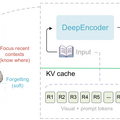
大規模言語モデル(LLM)をデコーダーに採用したOCRモデルが注目を集めています。LLMをデコーダーとして用いることで、言語の文脈知識を推論に活かせるため、認識精度が向上するというメリットがありますが、その一方で、出力するテキストが長くなるほど「KVキャッシュ」(過去の計算結果のメモリ保持)が累積し、メモリ消費量が増加するとともに、テキストの生成速度が低下していくという課題を抱えていました。
研究チームはこの課題を解決するため、人間の書き写し作業におけるワーキングメモリの仕組みを模倣した、アテンション機構「Reference Sliding Window Attention」(R-SWA)を提案しました。
人間が本を書き写す際、これまでに書き終えた膨大なページすべてを読み返すことはせず、手元の参照元の本と直前に書いたわずかな文字だけを確認しながら次の文字を書き進めます。
R-SWAはこの認知プロセスを再現しており、生成される各トークンは、すべての参照トークンにアクセスできる一方で、過去の出力テキストに関しては直近の一定数(標準で128個)のトークンに絞ってアテンションを向けます。これにより、ドキュメント全体の視覚情報を正確に保持しつつ、デコード中のKVキャッシュのサイズを一定に保つことに成功しました。
このR-SWAを、高い画像圧縮率を持つDeepSeek OCRのエンコーダー「DeepEncoder」と組み合わせることで、Unlimited OCRは標準的な32Kトークンの最大長において、数十ページに及ぶドキュメントをわずか1回の計算でテキスト化できるようになりました。
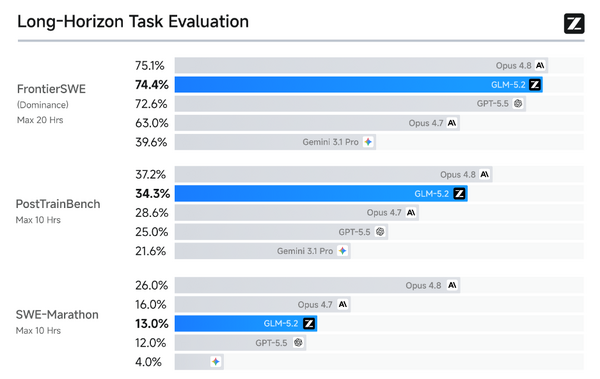
性能評価において、Unlimited OCRはドキュメント解析のベンチマーク「OmniDocBench v1.5」で93.23%という総合スコアを記録し、DeepSeek OCR 2の89.17を上回る結果を達成しました。
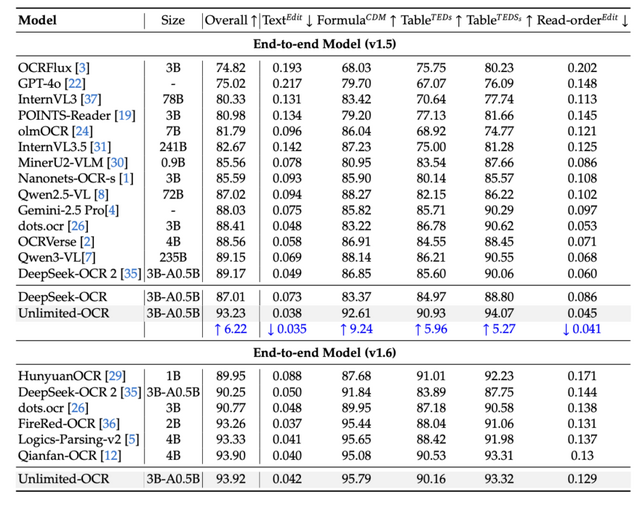
▲OmniDocBench(v1.5/v1.6)における各エンドツーエンドモデルの比較