



この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第147回)は、NVIDIA開発の物理AI向けオープンソースの世界モデル「Cosmos 3」や、ノートPCで動くGoogleのマルチモーダルAI「Gemma 4 12B」を取り上げます。
また、文章からマンガを生成する国産AI「MangaFlow」や、Baiduが開発した軽量なオープンソース文書解析AI「PaddleOCR-VL-1.6」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、使うほど育つ自己改善型AIエージェント「Hermes Agent」の専用デスクトップアプリ「Hermes Desktop」を別の単体記事で取り上げています。

NVIDIA、物理AI向けオープンソースの世界モデル「Cosmos 3」発表 言語・画像・動画・音声・行動を単一構造で統合
NVIDIAはロボットや自動運転といったPhysical AI向けのモデル「Cosmos 3」を発表しました。これは言語・画像・動画・音声・行動という5つのモダリティを、単一のアーキテクチャでまとめて処理・生成できる世界モデルです。
これまで、状況を理解する視覚言語モデル、未来を映像で予測する動画生成モデル、動きを決める行動予測モデルは別々に作られてきましたが、Cosmos 3はそれらを一つの枠組みに統合しました。
評価面では、スマートインフラや自動運転の各ドメインではオープンソースモデルだけでなくGemini 3.1 Proなどのクローズドモデルも上回りました。
後処理済みモデルは、Artificial AnalysisのリーダーボードでオープンウェイトのText-to-Image・Image-to-Video部門でいずれも1位、ロボット制御ではRoboLab・RoboArenaの両ベンチマークで1位を獲得しました。
モデルは「Edge」「Nano」「Super」の3サイズが用意され、今回はNanoとSuperが公開されています。

文章からマンガを生成する国産AI「MangaFlow」を東大などが開発
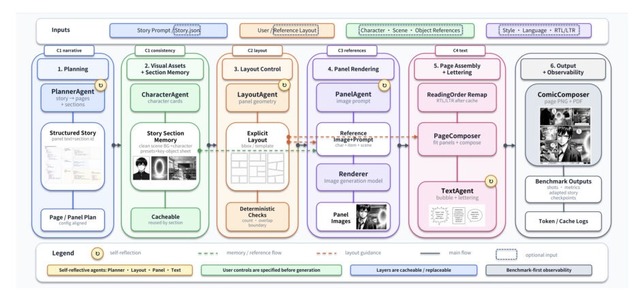
東京大学と香港科技大学(広州)の研究チームが、文章から一貫性のあるマンガを自動生成するAIシステム「MangaFlow」を発表しました。
従来の画像生成AIでは、マンガのページ全体を一度に出力しようとするため、指定したコマ割りが崩れたり、ページが変わるとキャラクターの見た目まで変わってしまうという大きな課題がありました。
この問題を解決するため、MangaFlowはマンガ制作を人間の作業のように分割しているのが特徴。「ストーリー計画」「コマ割り」「作画」「セリフ配置」などを別々のAIが連携して処理します。
さらに独自の記憶機能を採用し、特定のシーンにおける登場人物のキャラ・シーン・オブジェクトなどの設定をAIが保持することで、複数のコマにわたってキャラクターの姿がブレるのを防いでいます。
また、コマの配置やサイズをユーザーが自由に指定したり、参考となる既存のマンガの構図をそのまま流用したりと、クリエイターの意図を反映した細かな調整ができます。





MangaFlow: An End-to-End Agentic Framework for Controllable Story to Manga Generation
Muyao Wang, Zeke Xie, Yanhao Chen, Lixin Xiu, Hideki Nakayama
Paper
Google、ノートPCで動くマルチモーダルAI「Gemma 4 12B」公開
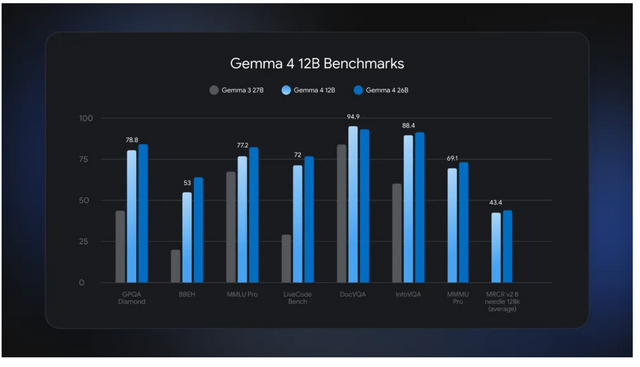
GoogleはAIモデル「Gemma 4 12B」を発表しました。クラウドに頼らず手元のノートパソコンで動かせるのが特徴で、画像や音声も扱えるマルチモーダルAIでありながら、16GBのメモリがあれば動作します。
小型のE4Bと上位の26B MoEモデルの中間にあたり、中型モデルとしては音声入力に標準対応しました。
従来のマルチモーダルAIは画像や音声を専用のエンコーダーを通してから言語モデルに渡していましたが、これは処理が重くメモリも多く消費します。Gemma 4 12Bはこのエンコーダーを使わず、画像や音声を直接言語モデルに取り込む構成にすることで、動作を軽く、速くしました。
性能は26Bモデルに迫る一方、メモリ消費は半分以下です。オフラインでも音声の文字起こしや翻訳ができ、複雑な処理も手元のパソコンでこなせます。
ライセンスはApache 2.0で自由に利用できます。


Gemma 4 12B
Google
GitHub | Blog | Hugging Face
軽量なオープンソース文書解析AI「PaddleOCR-VL-1.6」をBaiduが発表。0.9Bで巨大モデル超えの精度
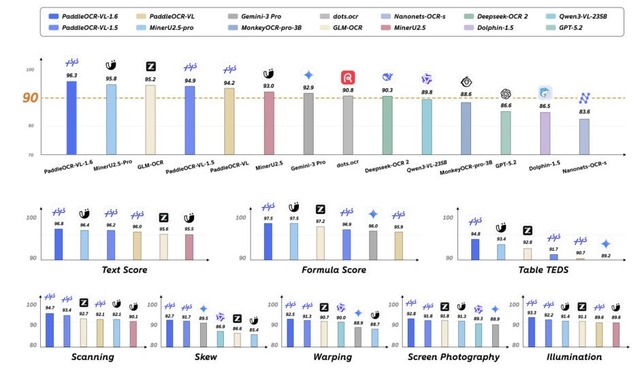
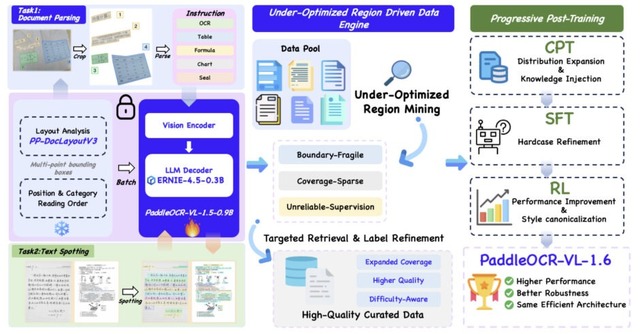
「PaddleOCR-VL-1.6」は、Baiduが発表した文書解析向けの軽量AIモデルです。前バージョンの1.5を改良したもので、0.9Bというコンパクトさを保ちながら、文書ベンチマークのOmniDocBench v1.6で96.33%という最高水準のスコアを達成しました。
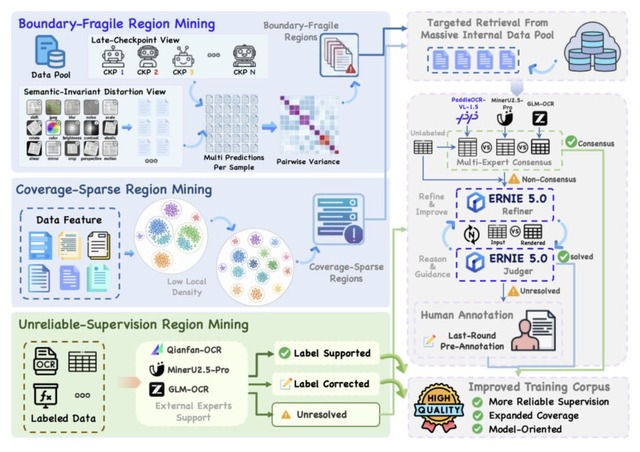
ポイントは、学習データをただ増やすのではなく、前モデルが苦手な部分だけを狙って補強したことです。具体的には、画像が少しずれただけで答えが変わる不安定な箇所、似た例が少なくて学習しきれていない箇所、そもそも正解ラベル自体が間違っている箇所、という3つの弱点を見つけ出して重点的に直しました。
結果として、表の認識精度が伸び、実世界に近い条件の文書解析テスト「Real5-OmniDocBench」でも首位になりました。また、235BのQwen3-VLやGemini 3 Proといった大きなモデルすら上回りました。
PaddleOCR-VL-1.6: Expanding the Frontier of Document Parsing with Under-Optimized Region Refinement and Progressive Post-Training
Zelun Zhang, Hongen Liu, Suyin Liang, Yubo Zhang, Yiqing Xiang, Jiaxuan Liu, Ting Sun, Manhui Lin, Yue Zhang, Changda Zhou, Tingquan Gao, Cheng Cui, Yi Liu, Dianhai Yu, Yanjun Ma
Paper | GitHub | Hugging Face